🔬 RamanBench Leaderboard
RamanBench is a large-scale benchmark for machine learning on Raman spectroscopy, unifying 74 publicly available datasets (163 prediction targets) across four application domains — Material Science, Biological, Medical, and Chemical — covering both classification and regression tasks and spanning diverse instruments and experimental conditions. We compare 28 models, from the domain standard PLS to modern tabular foundation models (TabPFN, TabICL) and time-series classifiers (ROCKET, ARSENAL).
Elo is calibrated so Random Forest = 1000.
Score is a combined normalized performance index based on F1 (classification) and RMSE (regression) — best model per target = 1, median = 0; higher is better.
Improvability % is the mean relative gap to the best model per target (lower is better).
v0.1.0
{kind=link}
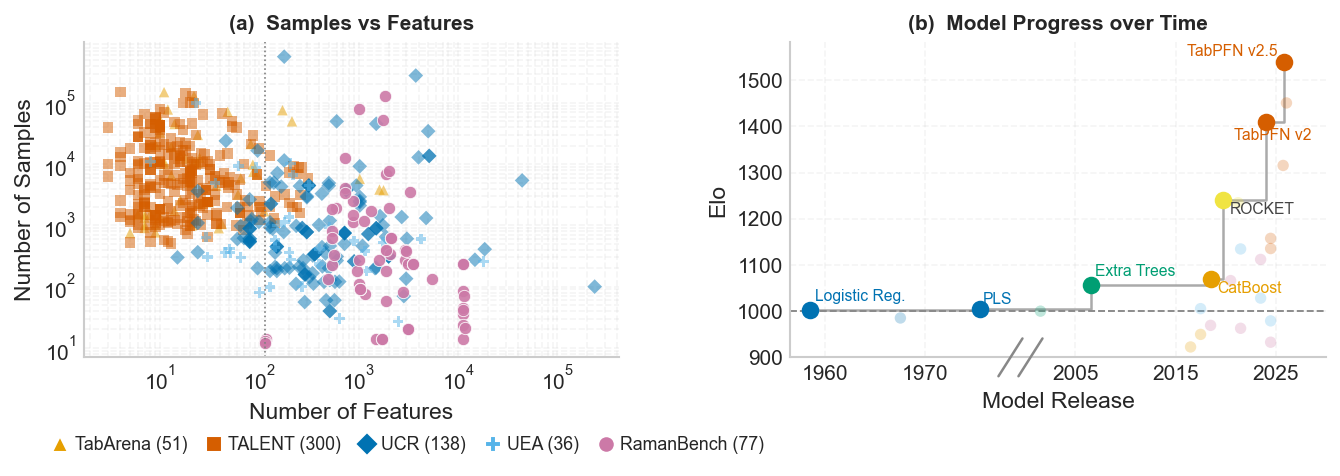
Left: RamanBench datasets (pink) occupy a high-dimensional, low-sample regime distinct from tabular benchmarks (TabArena, TALENT) and time-series benchmarks (UCR, UEA). Right: Model performance (Elo) vs. release year. PLS, the long-standing domain standard, held its leading position for decades; only in the last decade have modern methods begun to clearly surpass it. The state-of-the-art frontier is still advancing — no single model dominates across all tasks and domains.
{kind=link}
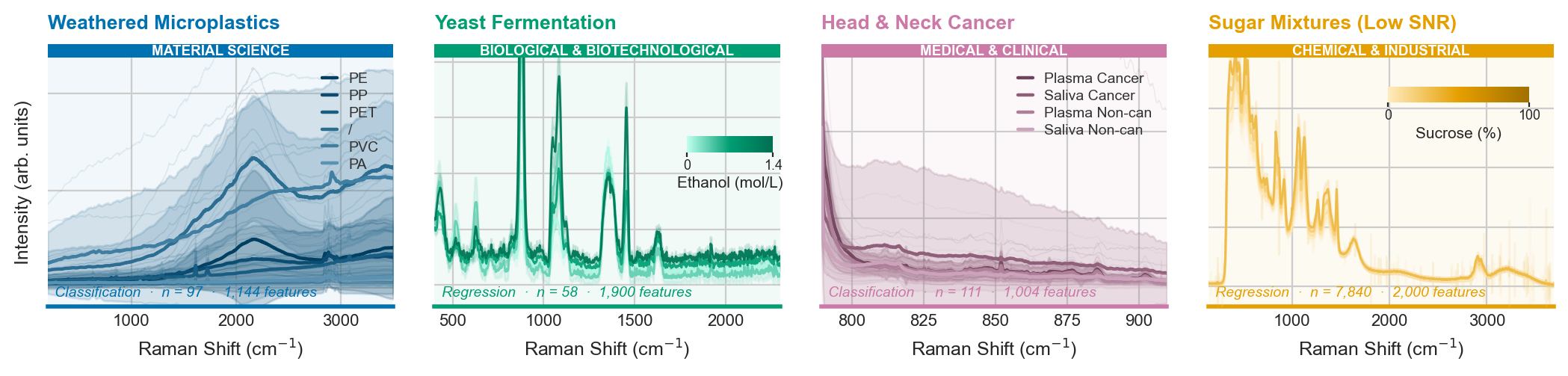
Representative Raman spectra from the four application domains in RamanBench. Each panel shows spectra from one domain, colored by class (classification) or by the target analyte value (regression, gradient from low to high). The thick line is the mean spectrum; shaded bands show ±1 standard deviation. Spectral ranges, sample sizes, noise levels, and analytical tasks differ substantially across domains, illustrating the breadth and heterogeneity of RamanBench.
{kind=link}
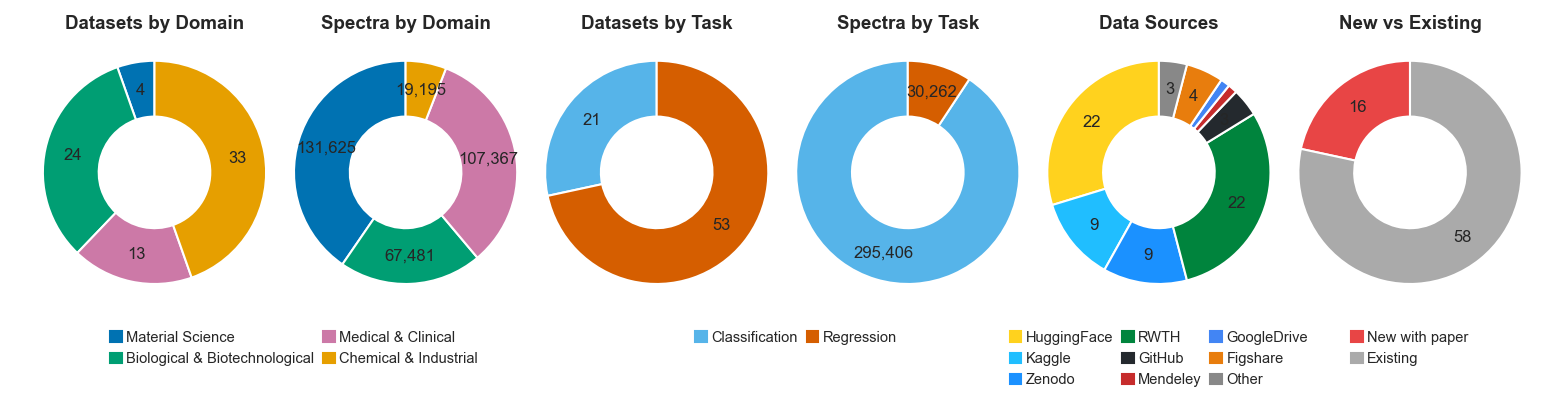
Benchmark composition overview. Domain distribution (left two donuts): Chemical & Industrial contributes the most datasets (33 of 74), while Material Science dominates by raw spectrum count due to the large RRUFF mineral library and MLROD. Task distribution (centre two donuts): Regression datasets outnumber classification (53 vs. 21), yet classification datasets account for over 91% of all spectra. Data sources (fifth donut): Datasets originate from eight hosting platforms with HuggingFace and Kaggle being the two largest. New vs. existing (sixth donut): 16 of the 74 datasets (★) are released for the first time with this paper.
{kind=link}
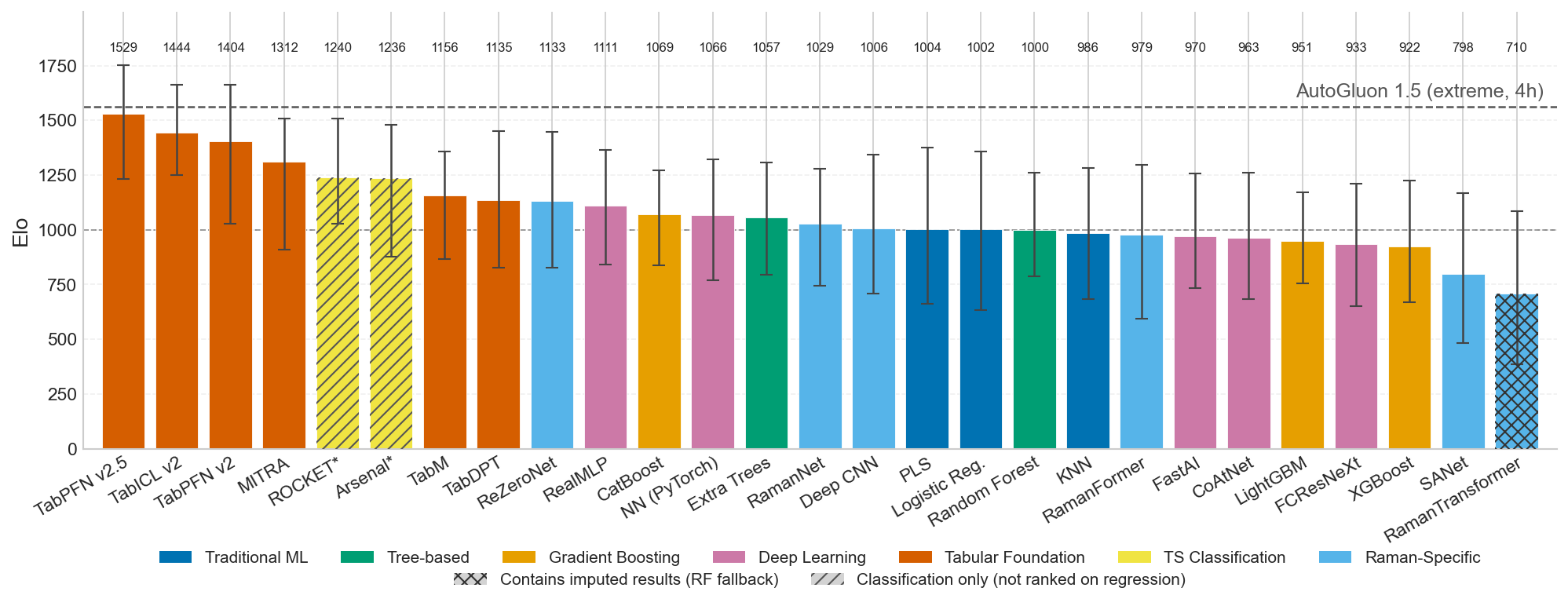
RamanBench Leaderboard. Elo ratings for all models (RF = 1000), sorted by performance. Error bars show 95% bootstrap confidence intervals (200 resampling rounds over the target pool). Models are colour-coded by algorithmic family. A higher Elo indicates consistently better performance across all classification and regression targets. Models marked with * are evaluated on classification tasks only and not imputed on regression tasks.
Combined ranking across all tasks. Score is normalized performance averaged across classification (F1) and regression (RMSE) datasets — best model per dataset = 1, median = 0.